
rancher 1.6 实践指南-2
前言:
话说认识rancher应该是14年,当时我还在某人寿公司,为了在vmware上自动化部署应用环境而大搞ansible。后来我跳槽到新东方搞容器云,这才正儿八经的研究rancher的落地方案。rancher是个轻量级方案,可探索的东西很多,很多组件需要自己实施补全。除了在项目中自己反复实践和摸索外,也受到rancher社区成员实践讨论或者技术分享的启发,因此我也总结一片日志,把一期项目彻底总结沉淀一下。一是来源于社区再回馈社区,看看是否对大家有启发,二是准备卸下之前的工作成果,整理着装继续上路。 转载请注明出处:http://jiangjiang.space
目录:
目录注:
由于篇幅问题,这篇日志比较长,我会陆续更新上来。
本文是第二篇,记录rancher的部署方案。 –最后更新日期 20180413
2.3 rancher server db的高可用选择
以下配置过程摘自新东方信管部资深dba傅邵峰老师的文档,由于我并没有按照步骤复现整个过程,因此很有可能步骤有纰漏,这里主要是引出架构,具体实践过程就作为参考吧
2.3.1 选择一种数据库高可用的方案
20180404 note: 现在回头看看,当时我把简单的事情搞复杂了,cattle库并不大, 一套MySql主从也就搞定了,上MGC+MaxScale有点大材小用了。 现在的主要收益就是数据库挂了不影响rancher,省事了。
市面上常见的mysql高可用方案:
- Mysql 主从
- PXC/MGC
- MGR
数据库高可用方案有很多种,比较常见的是mysql主从方案,通过传送日志同步数据,一台出现问题则另一台可以转换为主节点,另一台恢复后作为从节点加入。在DNS上做ip映射,rancher server 直接连接数据库的域名。 这个方案已经足够好了,作为生产运行方案也是可以接受的,毕竟rancher server 挂掉后不会直接影响到各个宿主机上的业务。只要能在数小时内恢复即可。
如果你的RTO要求比较高,或者像我一样只是希望数据库故障尽可能的对我透明,那么你可以考虑下面这个方案。
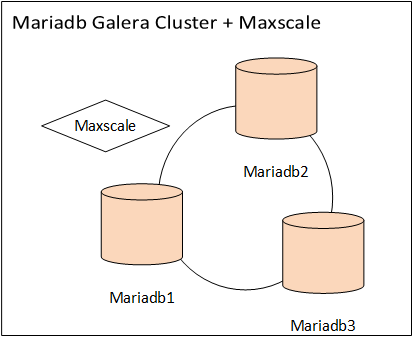
MGC+Maxscale中间件, MGC 是 mariadb galera cluster,是一套多主架构的分部署数据库方案,大概意思是说,任何一个数据库节点都是可以读写,写操作完成后要在集群内所有节点都写成功后操作才算完成。 这个方案在高并发场景下会有问题,对于rancher写数据库这个级别的并发还是可以的。
MaxScale中间件可以做到读写分离和负载均衡,其实以rancher写数据库的数据量暂时还用不到这么强悍的方案,全当是为将来的扩展有备无患吧。
选择这套方案的考虑
- 进一步减少切换时间,主从方案的切换时间至少是分钟级别的,我希望进一步减少可能的中断时间。
- 第二,用户无感知, 我需要的是完全透明的故障切换。(其实是因为我比较懒)
- rancher server 连接数据库串写死域名,所有的高可用都交给后面的数据库集群解决。
- 我和DBA都想玩一把这个方案试试。
2.3.2 MGC配置
首先,准备三台mariadb 服务器,安装mariadb,mariadb ,并组成gelara集群。
部署过程请参考下面两个文档。
https://mariadb.com/downloads 下载并安装mariadb 10.2
安装如下rpm包
MariaDB-client-10.2.11-1.el7.centos.x86_64
MariaDB-devel-10.2.11-1.el7.centos.x86_64
MariaDB-server-10.2.11-1.el7.centos.x86_64
MariaDB-common-10.2.11-1.el7.centos.x86_64
MariaDB-compat-10.2.11-1.el7.centos.x86_64
galera-25.3.22-1.rhel7.el7.centos.x86_64.rpm
jemalloc-3.6.0-1.el7.x86_64.rpm
jemalloc-devel-3.6.0-1.el7.x86_64.rpm
maxscale-2.1.7-1.x86_64 # maxscale可以复用其中一个数据库节点或者单独部署到一个机器。
mysql配置部分(略过)
# mysql配置略过,请参考本节最后的参考文档
[mysqld_safe]
open-files-limit = 65535
malloc-lib = /usr/local/lib/libjemalloc.so.2
galera配置部分
[galera]
wsrep_on = ON #开启全同步复制模式
wsrep_certify_nonPK = ON #为没有显式申明主键的表生成一个用于certificationtest的主键,默认为ON
wsrep_provider = /usr/lib64/galera/libgalera_smm.so #galera库文件路径
wsrep_provider_options = "gcache.dir = /data/mariadb10/galera;gcache.name=galera.cache;gcache.size=3G;gcache.page_size=3G"
wsrep_cluster_name = "MGC_Rancher"
wsrep_cluster_address = gcomm://<db1ip>,<db2ip>,<db3ip> #galera集群节点地址
wsrep_node_name = <db1hostname>
wsrep_node_address = <db1ip>
wsrep_slave_threads = 4
wsrep_sst_auth = backupusr:bak$2017Usr
wsrep_sst_method = xtrabackup-v2
## 转载注明回忆书签 jiangjiang.space
执行:
mysql_install_db --defaults-file=/etc/my.cnf.d/server.cnf --user=mysql --datadir=/data/mariadb10/datafile/
mysqld_safe --defaults-file=/etc/my.cnf.d/server.cnf --user=mysql --wsrep-new-cluster &
建立cattle数据库和用户(连接任何一个galera实例执行):
CREATE DATABASE IF NOT EXISTS cattle COLLATE = 'utf8_general_ci' CHARACTER SET = 'utf8';
GRANT ALL ON cattle.* TO 'cattle'@'%' IDENTIFIED BY 'cattle';
GRANT ALL ON cattle.* TO 'cattle'@'localhost' IDENTIFIED BY 'cattle';
创建maxscale监控用户(连接任何一个galera实例执行):
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'scale_monusr'@'%'
GRANT SELECT ON `mysql`.`tables_priv` TO 'scale_monusr'@'%'
GRANT SELECT ON `mysql`.`db` TO 'scale_monusr'@'%'
GRANT SELECT ON `mysql`.`user` TO 'scale_monusr'@'%'
GRANT FILE, SHOW DATABASES ON *.* TO 'cattle'@'%'
GRANT SELECT ON `mysql`.`user` TO 'cattle'@'%'
GRANT SELECT ON `mysql`.`tables_priv` TO 'cattle'@'%'
GRANT SELECT ON `mysql`.`db` TO 'cattle'@'%'
数据库准备完毕,下面是配置MaxScale。
参考文档:
https://mariadb.com/kb/en/library/what-is-mariadb-galera-cluster/
https://linux.cn/article-5767-1.html#3_2234
2.3.3 maxscale部署方法
我这里配置MaxScale复用其中一台数据库服务器。
如果怕MaxScale成为单点,还可以部署多个MaxScale,前面用LVS+Keepalived做四层负载均衡(可复用公司内部的公用4层转发)。实测MaxScale跑的很稳定,因此就没有做maxscale的高可用。
rpm -ivh maxscale-2.1.7-1.rhel.7.x86_64.rpm
mkdir /data/maxscale/{log,cache,pid,datafile} -p
chown maxscale.maxscale maxscale -R
maxscale 配置 /etc/maxscale.cnf
[maxscale]
threads = 3
ms_timestamp = 1
syslog = 1
maxlog = 1
log_to_shm = 0
log_warning = 1
log_notice = 1
log_info = 0
log_debug = 0
log_augmentation = 1
logdir = /data/maxscale/log/
datadir = /data/maxscale/datafile/
libdir = /usr/lib64/maxscale/
cachedir = /data/maxscale/cache/
piddir = /data/maxscale/pid/
execdir = /usr/bin/
max_connections = 2000
connection_timeout = 60
# Server definitions
# address of a MySQL server.
[server1]
type = server
address = ip1
port = 5306
protocol = MySQLBackend
serv_weight = 3
[server2]
type = server
address = ip2
port = 5306
protocol = MySQLBackend
serv_weight = 2
## 转载注明回忆书签 jiangjiang.space
[server3]
type = server
address = ip3
port = 5306
protocol = MySQLBackend
serv_weight = 1
# Monitor for the servers
[Galera Monitor]
type = monitor
module = galeramon
servers = server1,server2,server3
user = scale_monusr
passwd = <password>
monitor_interval = 1000
#detect_stale_master = true
# Service definitions
[Read-Write Service]
type = service
router = readwritesplit
servers = server1,server2,server3
user = cattle
passwd = <password>
use_sql_variables_in = master
enable_root_user = 1
master_accept_reads = true
max_slave_replication_lag = 900
max_slave_connections = 100%
[MaxAdmin Service]
type = service
router = cli
[Debug Service]
type = service
router = debugcli
servers = server1
#Listener
[Read-Write Listener]
type = listener
service = Read-Write Service
protocol = MySQLClient
address = ip1
port = 4105
[MaxAdmin Listener]
type = listener
service = MaxAdmin Service
protocol = maxscaled
address = 127.0.0.1
port = 6603
[Debug Listener]
type = listener
service = Debug Service
protocol = telnetd
address = 127.0.0.1
port = 6604
启动 maxscale
/usr/bin/maxscale -f /etc/maxscale.cnf &
# 这里只是作为一个进程启动,推荐用systemd或supervisord管理起来。
参考资料:
https://www.jianshu.com/p/772e17c10e08
https://rancher.com/docs/rancher/v1.6/en/installing-rancher/installing-server/#single-container-external-database
https://linux.cn/article-5767-1.html#3_2234
2.3.4 用keepalived 做 Maxscale的高可用
MaxScale前增加一层LVS四层负载均衡(设备可复用c/s之间的负载均衡),那么这个方案就可以说是全模块无死角的负载均衡架构了。 但是我们实际实施的时候并没有采用这样的方案,考虑到 Rancher Server 和 Client断开一段时间后并不会影响主机上的容器运行。 这段时间完全可以做一些维护, 采用 Galera和Maxscale后已经大大的减少了数据库切换时间,并且实测MaxScale的稳定性很好,感觉没有必要再投入更多资源在MaxScale上。更何况加入更多的组件会使得整个系统的复杂度上升,这实际上增加了维护成本并且扩展了故障域,可靠性有可能不升反降。因此这个方案也只是停留在纸面上了。
这个方案的架构图更新为下面这样

这部分由于没有继续实践,因此暂时略过。有需要的朋友可以自己搞搞
分享一下个不靠谱的运维事件 :
前两天我登上测试环境看数据库,发现mgc的两个节点挂掉了, 只剩下一个节点在跑,而且这两个库已经挂掉两个月了,因为没做监控也根本不知道。 挂掉原因是外键冲突,我分析可能是前一段做测试,经常删除服务,新建服务,容器变动很频繁,因此导致了三个主库同步上的冲突。dba傅老师怀疑是这个版本的bug。anyway, 退一万步来说,我想这样的故障无感知还是挺满意的。。。 不过孰优孰略还请看官自行斟酌。。。。
2.4 rancher server / client 负载均衡和实现

2.4.1 rancher server 和 rancher server HA
rancher server 的ha配置,至少准备两台主机作为rancher server,启动rancher server的命令如下:
sudo docker run -d --restart=unless-stopped --name ranchersvr01-Prometheus-1.6.13 -e JAVA_OPTS="-Xms4096m -Xmx4096m" -e CATTLE_PROMETHEUS_EXPORTER=true -v /etc/localtime:/etc/localtime -p 8080:8080 -p 9345:9345 -p 9108:9108 rancher/server:v1.6.13 --db-host cattledb --db-port 4105 --db-user cattle --db-pass cattlepass --db-name cattle --db-strict-enforcing --advertise-address <本机IP>
启动的多个rancher server中还可以设置其中一个ranhcer server 为普罗米修斯的数据导出节点,增加如下配置配置如下:
-p 9108:9108
-e CATTLE_PROMETHEUS_EXPORTER=true
配置这两条后在prometheus中可以看到rancher server的状态

逐条解释一下配置:
--name ranchersvr01-Prometheus-1.6.13 # 为server容器取名,便于以后的升级
-e JAVA_OPTS="-Xms4096m -Xmx4096m" # rancher server java写的,设置JVM内存容量
-e CATTLE_PROMETHEUS_EXPORTER=true
-p 9108:9108 # prometheus rancher exporter 需要的端口
-v /etc/localtime:/etc/localtime # 时区
-p 8080:8080 # websocket 和 admin 界面
-p 9345:9345 # rancher HA listener
--db-host cattledb #以下都是数据库连接信息
--db-port 4105
--db-user cattle
--db-pass cattlepass
--db-name cattle
--db-strict-enforcing # 强制所有表有主键,从rancher v1.6.11开始
--advertise-address <本机IP> # HA消息
#
# 转载请注明 回忆书签 jiangjiang.space
我这里配置没有考虑 ldap和ad,如果需要ldap认证还需要挂载证书到rancher server,请查阅下面的配置文档
其他资料请参考:
https://rancher.com/docs/rancher/v1.6/en/installing-rancher/installing-server/#multi-nodes
https://rancher.com/docs/rancher/v1.6/en/installing-rancher/installing-server/#ldap
2.4.2 在server/client之间增加负载均衡层(LVS+keepalived+Nginx)
2.4.2.1 常见的SLB组合:Lvs+Keepalived+Nginx
SLB (Server load Balancer) 又称4/7层转发或反响代理。顾名思义,这套系统使用我们普通的x86服务器搭建,是同时工作于TCP 4层和 7层的负载均衡方案,目前广大的互联网行业都是采用类似的方案将自己的业务接入公网。与此对应的方案还有F5公司的负载均衡设备GTM和LTM,以及A10公司的负载均衡等等。这些公司的产品是经过特殊优化的网络设备,有自己独特的硬件和软件架构,附加功能多,价格也相对昂贵。一般金融企业广泛采用F5的方案。

目前常用的负载均衡配置是LVS-DR模式,简单的解释一下工作原理,LVS—DR又前方的派发器和真实服务器组成,派发器上配置虚拟IP(VIP),当公网的一个用户发送请求给VIP后,派发器通过修改目的MAC地址的方式将请求转发给后端的真实服务器,真实服务器接到请求后,直接回应给公网上的用户。 这期间通过四层转发将tcp连接指派到某一个真实服务器上,真实服务器再通过7层代理将请求代理给后端的源站,源站返回后再有真实服务器回复给用户。

LVS的安装配置: https://www.jianshu.com/p/e146a7a14b4b
2.4.2.2 LVS-DR+Nginx负载均衡在rancher架构中的应用
实际上,rancher host 上的agent是通过websocket方式长连接到 rancher server上的,随着agent的增加,server也就自然承受更多的压力,此时就考虑增加server的数量。那么就形成了多个agent对多个server的情况。 如何做到更简单有效的扩容呢?那就需要在server和host之间增加一层中间层,也就是负载均衡层。 这样负载均衡连接的两端在任何时候都可以扩展,不需要停机,也不互相影响。 两端扩容的数量也可以达到相当大的数目,试想一下当你在互联网秒杀的时候,是不是有成千上万的客户端通过负载均衡连接后端成百上千的服务器呢? 这是一个道理,你可以吧rancher host当作秒杀时候的浏览器,把rancher server 当场是某东或某宝的交易服务器。而rancher host 和server之前跑的不是抢购商品,而是互相交换消息。
如下图:

加入负载均衡后的好处:
- 负载确实均衡了,agent连接上来后会有多个server为它服务
- 解耦,agent的连接串永远不用变,只需要写负载均衡器上的虚拟地址即可,后端无论怎么变化都不影响agnet的配置
- 好扩展,如果要增加server,只需要简单的在Nginx中增加upstream的配置,然后一刷新就ok了。
LVS Keepalived 配置
LVS1 : 配置keepalived,配置虚拟ip,配置到Nginx1和Nginx2的转发
LVS2 : 配置keepalived,配置虚拟ip,配置到Nginx1和Nginx2的转发
Nginx1 :配置nginx 到 rancher server 8080 上的转发
Nginx2 :配置nginx 到 rancher server 8080 上的转发
LVS配置
vrrp_instance RANCHER {
state MASTER
interface eth0
virtual_router_id 109
priority 50
advert_int 3
authentication {
auth_type PASS
auth_pass rancher
}
virtual_ipaddress {
<VIP地址>/22 brd <广播地址> dev eth0 label eth0:30
}
}
virtual_server <VIP地址> 80 {
delay_loop 3
lb_algo rr
lb_kind DR
persistence_timeout 3600
protocol TCP
real_server <Nginx-1-ip> 80 {
weight 10
HTTP_GET {
url {
path http://<Nginx-1-ip>/do_not_delete/lvs.html
#设置一个健康检查页
status_code 200
}
connect_port 80
connect_timeout 5
nb_get_retry 3
delay_before_retry 2
}
}
## 转载注明回忆书签 jiangjiang.space
real_server <Nginx-2-ip> 80 {
weight 10
HTTP_GET {
url {
path http://<Nginx-2-ip>/do_not_delete/lvs.html
status_code 200
}
connect_port 80
connect_timeout 5
nb_get_retry 3
delay_before_retry 2
}
}
}
#如果愿意还可以配置https 443
Nginx节点配置
Nginx节点配置分为两部分:
- 虚拟IP(VIP)设置到回环设备上(lo),当接收到lvs发来的包后本机网卡才会处理这些包。
- 设置Nginx的Websocket转发到rancher server的8080端口上
VIP配置在lo上的配置:
在nginx节点上新增一个service: /etc/init.d/realserver
配置文件如下:
#!/bin/bash
# chkconfig: - 95 15
# Source function library.
. /etc/init.d/functions
LVSDEV_LO3="lo:10" # 绑定设备
LVSIP3="<vip>" # vip
RETVAL=$?
start() {
echo 0 >/proc/sys/net/ipv4/ip_forward
echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
/sbin/ifconfig $LVSDEV_LO3 $LVSIP3 broadcast $LVSIP3 netmask 255.255.255.255 up
/sbin/route add -host $LVSIP3 dev $LVSDEV_LO3
}
stop() {
test_dev=`ifconfig | awk '/^[a-z]/{ print $1 }' | grep $LVSDEV_LO3`
if [ -n "$test_dev" ]; then
echo "info: Shutdown $LVSDEV_LO3 network interface."
ifconfig $LVSDEV_LO3 down
fi
## 转载注明回忆书签 jiangjiang.space
echo "info: Clearing hiding. "
echo 0 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 0 > /proc/sys/net/ipv4/conf/lo/arp_announce
echo 0 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 0 > /proc/sys/net/ipv4/conf/all/arp_announce
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart|reload)
stop
start
RETVAL=$?
;;
*)
echo $"Usage: $0 {start|stop|restart}"
exit 1
esac
exit $RETVAL
# 配置文件编辑好后启动服务:
chkconfig --add realserver
service realserver start
# 随后在另一台nginx节点上重复以上配置
下面设置Nginx的Websocket转发到rancher server的8080端口上。
安装nginx过程略过,在conf.d中增加虚拟主机配置。
vi /usr/local/nginx/conf/conf.d/rancher.conf
upstream rancher {
server <rancherserver1>:8080 weight=10; # rancher server的IP地址
server <rancherserver2>:8080 weight=10;
keepalive 200;
}
map $http_upgrade $connection_upgrade {
default Upgrade;
'' close;
}
## 转载注明回忆书签 jiangjiang.space
server {
listen 80 ;
server_name rancher.cn; # 如果给vip配置了域名则写在这里,没有域名就写ip,如果用https则必须配置域名。
location / {
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Port $server_port;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://rancher;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
proxy_read_timeout 900s;
}
}
# 如需要还可以自行增加https 配置请参考rancher官方文档
配置好后,直接访问 http://VIP:80 应该就可以看到控制台界面了。如果没有则是配置错误,继续调整。
参考文档:
https://www.cnblogs.com/liwei0526vip/p/6370103.html
https://rancher.com/docs/rancher/v1.6/en/installing-rancher/installing-server/basic-ssl-config/#example-nginx-configuration
2.4.3 rancher Host
此时再增加custom host的时候, 你会发现最后的URL连接地址变为vip(或者你配置的vip的域名)

## 转载注明回忆书签 jiangjiang.space
sudo docker run --rm --privileged -v /var/run/docker.sock:/var/run/docker.sock -v /var/lib/rancher:/var/lib/rancher rancher/agent:v1.2.9 http://vip/v1/scripts/xxxxx ### 注意这里,自动变为vip或者你的域名
直接贴到host上执行即可。
2.5 volume rancherNFS和glusterFS
我目前的环境中存储分为如下三个部分:
| 类型 | 实现方式 | 用途 |
| 本机volume | 本地sas盘+SSD加速 | 作为运行环境存储 |
| rancherNFS | 公司统一的NFS,采用NFSV4,物理机搭建 | 配置存储和读存储 |
| glusterFS | 公司统一的GFS,物理机搭建 | 作为共享写存储使用,直接挂载GFS上的子目录到容器里 |
2.5.1 rancher NFS
在NFS一侧export出来一个目录,将要连接的所有rancher host ip都写到nfs运行连接的配置中,注意edge节点不要写。
直接在社区商店中找到rancher NFS,启动应用,填写nfs对应的ip和export的目录即可。
2.5.2 glusterFS
以前ranhcer 商店中也有glusterFS的应用,后来听说是bug太多就去掉支持了。弄的我现在就比较尴尬。 我目前的做法就是在所有rancher host上挂载glusterFS的目录,哪个应用要用就直接用docker的volume映射到容器里面,目录不存在也没事,映射的时候会自动创建。
这里需要注意下, 如果启动docker的时候systemd里面的 mountflag为private,gfs目录就无法挂载上去,需要修改为shared。这个在前一篇日志里有说明。
/usr/lib/systemd/system/docker.service
